
How Claude Code Design Prompt Caching
Introduction
Recently I was using Claude Code on third-party APIs. From the API pricing alone, for example, Kimi is 25% of Anthropic API price. But after comparing the actual cost for the same task, Kimi ends up at roughly 50% of the cost — not the 75% saving you would expect from the raw token price. The gap between “cheap model” and “cheap session” is real, and one of the key reasons is that Claude Code is exceptionally well-designed around prompt caching, which is tightly coupled with the Anthropic API.
To understand how this works, one key fact is essential: Anthropic’s cache is cumulative. A hit on breakpoint 4 means breakpoints 1, 2, and 3 are all hits too. So the four cache breakpoints in Claude Code are not four independent caches — they are four anchor points that give the cache multiple fallback positions when any part of the prompt changes.
In this blog, we will go through what these breakpoints are, how they enable 80%+ cache hit rates in long sessions, and how context compaction interacts with caching in a way that can quietly drain savings if not designed carefully.
Four Breakpoints in Claude Code
The Four-Layer Layout
Claude Code structures every API request with four cache breakpoints, ordered by Anthropic’s cache prefix order (tools → system → messages):
| Breakpoint | Content | Typical Size | Change Frequency |
|---|---|---|---|
| bp1 | Tool definitions (cache_control placed on the last tool) | 5–15K tokens | Only when MCP server config changes |
| bp2 | Static system prompt (role, rules, formatting) — cached globally across all organizations | 4–8K tokens | Only on Claude Code version upgrade |
| bp3 | Dynamic system prompt (CLAUDE.md, project metadata, git status, env vars) — session-specific | 1–5K tokens | Stable within a session |
| bp4 | Rolling anchor on the current conversation | 0 – tens of K | Every turn |
The system prompt is split internally at SYSTEM_PROMPT_DYNAMIC_BOUNDARY — everything before the boundary (static instructions, tool descriptions) is shared in a cross-organization cache, while everything after (your CLAUDE.md, env, date) is session-specific. This split is part of why bp2 hits cost almost nothing even on the very first request of a brand-new session.
A simplified view of the actual request structure:
{
"model": "claude-sonnet-4-6",
"tools": [
{"name": "Bash", ...},
{"name": "Edit", ...},
# ... many tools
{"name": "Task", ...,
"cache_control": {"type": "ephemeral"}} # bp1 — on the last tool
],
"system": [
{"type": "text", "text": STATIC_SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"}}, # bp2 — pre-SYSTEM_PROMPT_DYNAMIC_BOUNDARY
{"type": "text", "text": CLAUDE_MD + ENV_CONTEXT,
"cache_control": {"type": "ephemeral"}} # bp3 — post-boundary, session-specific
],
"messages": [
{"role": "assistant", "content": "..."},
{"role": "user", "content": "..."},
# ... conversation history ...
{"role": "user", "content": [
{"type": "text", "text": LATEST_USER_MESSAGE,
"cache_control": {"type": "ephemeral"}} # bp4 — rolls every turn
]}
]
}
The Rolling Breakpoint
bp1, bp2, and bp3 stay in the same position unless the tool list, system prompt, or CLAUDE.md changes. bp4 is the interesting one: it is a rolling anchor that moves to the end of the latest user message on every turn.
Here is what happens across three consecutive turns:
- Turn 1: All four
cache_controlmarkers fire simultaneously. Every token is written to cache at 1.25x cost. This is the one-time startup cost of a session. - Turn 2: bp1, bp2, bp3 all hit (cache read, 0.1x). Only the new content since bp4’s last position — the assistant’s response to turn 1 and the new user message — needs to be written as a cache delta.
- Turn 3: bp4 advances again. The turn 2 content is now in the cache too. Each turn, only the freshest few hundred to few thousand tokens require a new write.
The billing model matches this: when Anthropic sees a cache_control at bp4, it does not charge for rewriting everything from the start. It finds the deepest prefix already in cache (e.g., bp3), then charges only for the delta after that point. So a typical turn 2 response looks like:
{
"cache_read_input_tokens": 15000,
"cache_creation_input_tokens": 1100,
"input_tokens": 0
}
Fifteen thousand tokens read at 0.1x, a thousand-token delta written at 1.25x — instead of paying for the full 16K at normal rates.
Why 80%+ Cache Hit Rates Are Achievable
A concrete example makes this clear. Suppose a session has reached turn 10:
| Component | Tokens | Status at Turn 10 |
|---|---|---|
| Tool definitions | 8,000 | cache read |
| System prompt | 5,000 | cache read |
| CLAUDE.md / env | 2,000 | cache read |
| Turns 1–9 (accumulated) | ~18,000 | cache read |
| Latest assistant response | 2,000 | new cache write (delta) |
| Latest user message | 400 | new cache write (delta) |
| Total | ~35,400 | |
| Cache hit rate | 33,000 / 35,400 = 93% |
The longer the session, the better the ratio. Each turn adds only a small fresh delta while the cached prefix keeps growing. This is why switching to a cheaper model but losing this caching structure delivers disappointingly modest savings — you are paying close to full price for most tokens on every call.
Why Four Breakpoints Instead of One
Theoretically, a single bp4 at the very end would cache the entire prefix. Four breakpoints exist because different events bust the cache at different layers:
| Event | What breaks |
|---|---|
| MCP server added or removed | bp1 onward (tool list changed) |
| Claude Code version upgrade | bp2 onward (static system prompt changed); sometimes bp1 if tool descriptions ship updated too |
| CLAUDE.md or env edited | bp3 onward |
| Normal turn | Only bp4 moves |
| Context compaction | Messages prefix rewritten — bp4 zone |
With four breakpoints, each event only invalidates from its layer downward. If you only used one breakpoint and CLAUDE.md changed slightly, the entire prefix would need to be rewritten. With four, only bp3 and beyond get invalidated — bp1 and bp2 survive untouched.
Anti-Patterns That Collapse Hit Rates
Several common patterns silently destroy cache efficiency:
# Bad: dynamic content injected into system prompt
system_prompt = f"""
You are Claude Code.
Current time: {datetime.now()} # different every call → bp2 always misses
Working directory: {os.getcwd()} # changes on cd → bp2 always misses
"""
# Good: keep system prompt fully static
system_prompt = "You are Claude Code."
messages = [{"role": "user", "content": f"[ctx: time={now}] {query}"}]
# Bad: conditional tool lists based on query content
if "database" in query:
tools = base_tools + db_tools
else:
tools = base_tools # tool list differs → bp1 misses
# Good: always provide the full tool list, let the model decide
# Bad: summarizing history in-place
if len(messages) > 20:
summary = summarize(messages[:-5])
messages = [{"role": "user", "content": summary}] + messages[-5:]
# This rewrites the message prefix and forces bp4 to re-cache — then you pay again next turn
# Bad: switching models mid-session
# Turns 1–5: Sonnet 4.6
# Turn 6: switch to Haiku → different KV cache pool → all cache lost
# Also bad: switching providers mid-session (even for the same model)
# Turns 1–5: Fireworks
# Turn 6: Cloudflare → different cache pool → all cache lost
When to Use 1-Hour TTL
Claude Code defaults to a 5-minute TTL. If agent tool calls are slow (database queries, human approval gates, batch jobs), use the 1-hour TTL option:
| TTL | Write Cost | Best For |
|---|---|---|
| 5 minutes | 1.25x | Continuous conversation, interaction every few minutes |
| 1 hour | 2x | Slow tools, human-in-the-loop, user stepping away mid-session |
The math is straightforward: the 1-hour option costs 0.75x extra at write time. As long as the cache gets at least one additional read hit that would otherwise require a re-write, it pays off. If you expect any activity after a 5-minute gap, 1-hour TTL is usually the right call.
Context Compaction with Cache
The Core Conflict
Long sessions eventually hit a fundamental problem: caching wants history to be append-only, but compaction requires rewriting history. These two requirements are in direct conflict.
Prefix caching is physically a prefix match operation. If one token is different at position N, every K/V pair from position N onward has to be recomputed. Compaction by definition replaces old turns with a shorter summary — that is a prefix mutation, which busts the cache from that point on.
Without careful design, sessions fall into a cache cliff cycle: accumulate 50 turns of well-cached history → compact → pay a large cache write to rebuild the prefix → accumulate again → compact again.
What Naive Compaction Costs
Suppose the context has grown to 180K tokens and compaction triggers, replacing turns 1–40 with a 3K summary:
Before compaction: After compaction:
────────────────────────── ────────────────────────────
[Tools 8K] cache_read [Tools 8K] cache_read ✓
[System 5K] cache_read [System 5K] cache_read ✓
[CLAUDE.md 2K] cache_read [CLAUDE.md 2K] cache_read ✓
[Turns 1–40 165K] cache_read → [Summary 3K] WRITE (new anchor)
[Turn 41 new] cache_write [Turns 41–45] WRITE (rebuilt tail)
[Turn 46 new] WRITE (bp4)
bp1, bp2, and bp3 survive because tools, system prompt, and CLAUDE.md did not change. But from the summary onward, everything is a new prefix that must be written. This is a one-time cost — but only worthwhile if the session continues long enough to amortize it.
The rough economics:
Compaction cost ≈ LLM call to summarize + cache write of summary
≈ $0.05 (inference) + $0.02 (3K × 1.25x)
≈ $0.07 total
Savings per subsequent turn ≈ (165K compressed → 3K) × read discount
≈ ~$0.047 per turn
Break-even ≈ $0.07 / $0.047 ≈ 1.5 turns
If the session runs at least two more turns after compaction, it pays off. In practice sessions run dozens more turns, so compaction ROI is strong — as long as you do not compact too frequently.
Claude Code’s Compaction Strategy
Claude Code implements several specific behaviors to make compaction work well with caching.
Timing: compaction triggers at about 95% context utilization (~190K tokens), not at the limit. A warning appears around 85% (~170K). This gives the user a chance to trigger /compact manually and keeps compaction infrequent enough that each event gets amortized over many subsequent turns.
Structured summary prompt: when compaction fires, Claude Code asks the model to produce a focused summary that preserves:
- Completed tasks and key decisions
- What the user is currently doing
- File paths that have been modified
- Open questions and to-dos
- Any details the user explicitly asked to remember
It omits intermediate tool output, failed attempts, and casual conversation. This produces summaries of 3–5K tokens from 150K+ of context — a 30–50× compression ratio.
Preserving the recent tail: the summary does not replace the most recent turns verbatim. The post-compaction request structure looks like:
{
"tools": [
...,
{"name": "Task", ..., "cache_control": {"type": "ephemeral"}} # bp1 — survives
],
"system": [
{"type": "text", "text": STATIC_SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"}}, # bp2 — survives
{"type": "text", "text": CLAUDE_MD + ENV,
"cache_control": {"type": "ephemeral"}} # bp3 — survives
],
"messages": [
# Compaction summary as its own dedicated block with own cache_control
{"role": "assistant", "content": [
{"type": "compaction",
"content": SUMMARY_OF_OLD_HISTORY,
"cache_control": {"type": "ephemeral"}} # new summary anchor
]},
# Most recent turns kept verbatim
{"role": "assistant", "content": "..."}, # turn 41
{"role": "user", "content": "..."}, # turn 42
{"role": "assistant", "content": "..."}, # turn 43
{"role": "user", "content": "..."}, # turn 44
{"role": "assistant", "content": "..."}, # turn 45
# Current new turn
{"role": "user", "content": [
{"type": "text", "text": current_query,
"cache_control": {"type": "ephemeral"}} # bp4
]}
]
}
Notice that the compaction summary uses Anthropic’s dedicated "type": "compaction" content block — its own cache_control gives it a stable anchor of its own, so once written, every subsequent turn reads it back at 0.1x until the next compaction event. bp1, bp2, and bp3 all survive the compaction event because tools, system prompt, and CLAUDE.md were not touched.
Keeping the last few turns verbatim maintains model continuity (the model needs recent tool calls and responses for context), avoids hallucination from pure summary, and means those turns can keep hitting the cache until the next compaction.
1-hour TTL on the summary: the compaction summary is an expensive write investment. Using a 5-minute TTL risks having the cache expire if the user steps away for a few minutes, forcing a re-write. The 1-hour TTL protects the investment.
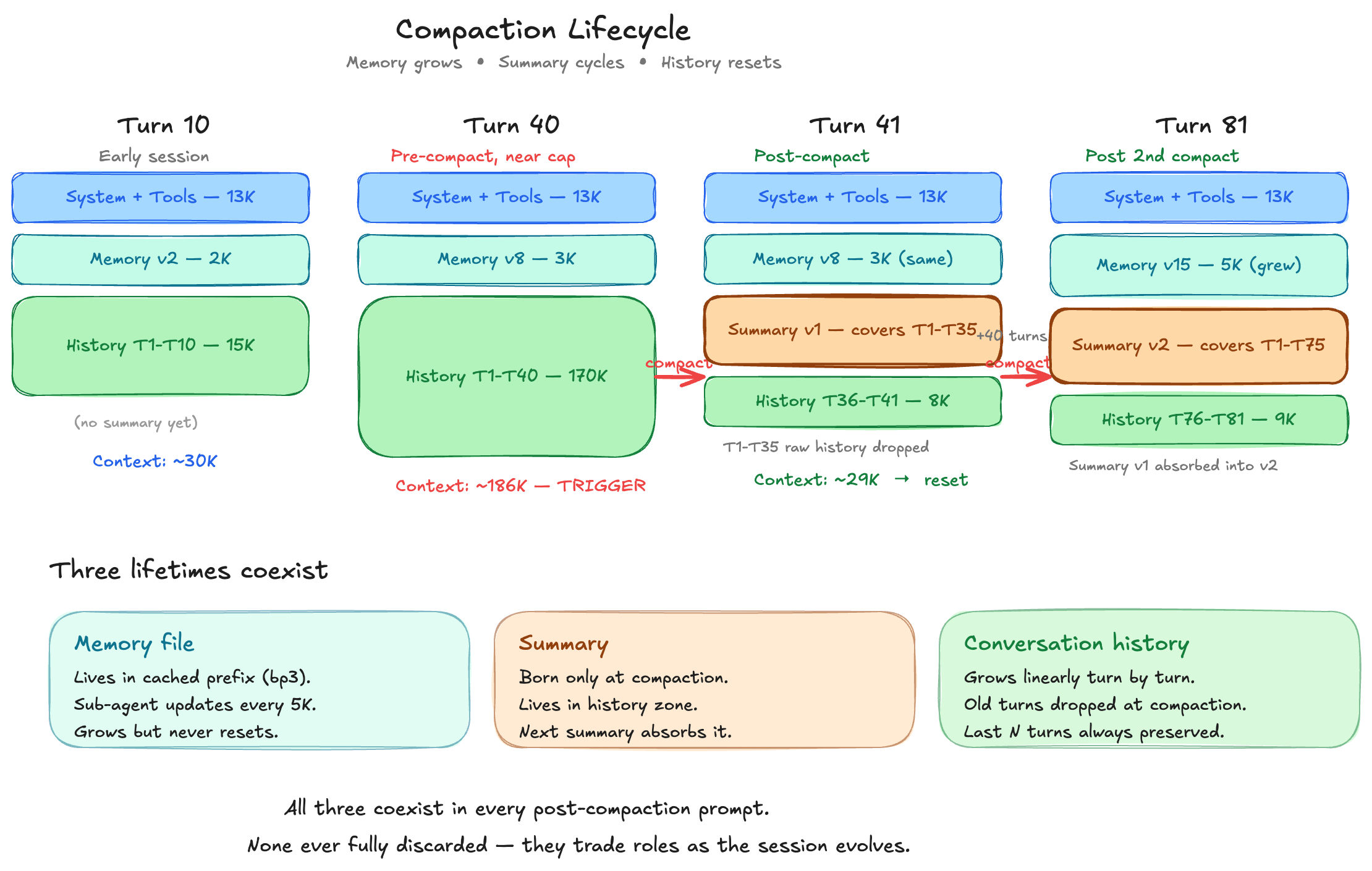
How CC control session memory and summary
As shown in the below diagram, memory and summary management are two independent processes — each is one of Claude Code’s five compaction strategies (Snip, Microcompact, Context collapse, Session memory, Full compact).
Session memory is controlled by a forked sub-agent which is updated per 5K tokens of accumulated conversation, and it lives alongside CLAUDE.md in the bp3 zone (dynamic system prompt half). The Full compact summary is only generated during compaction and occupies its own cache_control breakpoint as a dedicated compaction content block in the messages area. Both summary and memory co-exist in the prompt during every turn after compaction.
How Claude Code Avoids Compaction Entirely
The most important strategy is not managing compaction well — it is not needing it in the first place.
Task tool as sub-agent isolation: when the main agent uses the Task tool to delegate a subtask, that sub-agent runs in a completely separate conversation with its own 200K context window. It might read 30 files, run 10 grep commands, and accumulate 50K of exploratory content — none of which enters the main agent’s context. The main agent only sees the task input (a few hundred tokens) and the summary result (a few hundred to a few thousand tokens). This is context compaction at zero cost, with perfect cache isolation.
This is the real reason Claude Code recommends “use Task tool for complex exploration” — it is not just about modularity, it is about preventing the main context from growing in the first place.
File-based persistence: long-term information (project conventions, design decisions, to-do lists) gets written to CLAUDE.md rather than accumulating in the conversation. CLAUDE.md loads at session start into the bp3 region — stable, cached, and invisible to context growth.
Output pagination: the Read tool has a built-in token limit (~2000 lines). Long files use offset/limit parameters. Large command outputs get truncated with head/tail. Anything that goes into the conversation as a tool result stays in the history forever until compaction — keeping those results short delays the compaction point significantly.
Summary of Anti-Compaction Techniques
| Mechanism | Purpose | Cache Effect |
|---|---|---|
| Task tool | Isolates exploration in sub-agents | Large token counts never enter main context |
| CLAUDE.md | Persists project knowledge across sessions | Loads into stable bp3 cache |
| Read tool pagination | Limits single large outputs | Slows context growth |
| Auto-compact at 95% | Delays compaction to maximize amortization | One write investment covers more turns |
| Preserve last N turns | Keeps model continuity after compaction | Those turns stay cache-hot until next compact |
| 1-hour TTL on summary | Protects compaction write investment | Survives user pauses without re-write cost |
Conclusion
Claude Code’s caching design is not an add-on — it is built into the architecture of every single API call. The four-breakpoint layout matches the natural stability hierarchy of prompt content: system instructions and tool definitions almost never change, environment context is session-stable, and only the conversation tail evolves turn by turn. This structure, combined with cumulative prefix caching, is why long sessions can sustain 80–90% cache hit rates and why switching to a cheaper model without this structure yields much smaller savings than the raw token price suggests.
The context compaction story is equally deliberate. By delaying compaction to near the context limit, keeping the recent tail verbatim, giving the summary its own dedicated cache_control block, and routing heavy exploration through sub-agents via the Task tool, Claude Code keeps the cache hit rate from collapsing even as sessions run for hours.
For anyone building their own agents: the Task tool pattern — delegating exploratory subtasks to isolated sub-agents whose results come back as short summaries — is the single most effective technique to borrow. It simultaneously prevents context growth, preserves cache hit rate for the main agent, and produces cleaner conversation history.