
AI Agent
Recently, I came across the presentation made by Andrew NG and as shown in the screenshot below, he mentioned that the next frontier of AI is agent because the current state of AI interatction (like chatGPT) essentially asking an AI to complete a task in one go is limited. Than, the agentic workflow which would be a paradigm shift will be a more effective approach for AI problem-sovling. Instead of seeking a perfect output in a signle attempt, the method would invovle:
- Breaking down the task into smaller sub-tasks and multiple steps
- Allowing the AI to research, draft, and review
- Implement iterative improvement cycles

And also the fundation model company: Anthropic just dropped an incredible guide on “How To Build Effective Agents” and in that article, they mentioned that 2025 will be the year of AGENTS. Therefore, we are going to dive into the topic of AI agent/agentic AI in this blog.
What is an Agent?
In the early days of LLM, we solve tasks by passing the task to the LLM and directy using the model’s output as the answer to that problem. Now, we are moving towards the agentic workflow where we break down the task into smaller sub-tasks and multiple steps. For example, in chatGPT UI, we can prompt it and it will return a blog post about AI agent. But in the agentic workflow, we would break down the task into smaller sub-tasks and multiple steps. For example, the search tool would be called to query the relevant and recent information about AI agent, and then those information would be used by the LLM to write the blog post. After the draft is ready, the LLM would review the draft and then the final blog post would be returned. In the AI agent, the LLM is the brain that processes the task, plans a sequence of actions to complete the task, aggregate the results, and determines whether the task has been accomplished. By augmenting the LLM’s capabilities, three components are added to the agent:
- Tools: any function that the agent can use to complete the task
- Memory: short-term and long-term memory containing any information that the agent might need to reason about the actions it needs to take
- Planning: the capability of the agent to plan a sequence of actions to complete the task
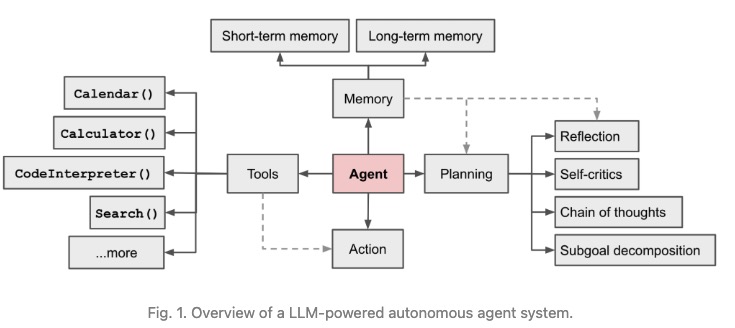
We will review the three components one by one.
Tools
LLM is good at generation. It can be regarded as the only capability of the LLM, i.e., text in, text out. And its capability is limited by its training data or embedded knowledge. Therefore, external tools can make agents extending its capability and having more capabilities. Tools help an agent to interact with the environment better. We can simply think of tools as the extension of the LLM’s capability. It can be classified into two types: reading and writing.
Reading actions
The agent can use the tool to read the information from the environment. The retriver tools, SQL exectuor, API call and web browing are all examples of reading tools. Those tools can allow the agent to have the more accurate and up-to-date information. Another type of reading tools are help the agent to overcome inherent model limitations. For example, while models often struggle with complex math, providing a calculator tool offers an easy solution. Similarly, tools like calendars, unit converters, and code interpreters can significantly enhance model capabilities. It can reduce hallucination and improve the accuracy of the LLM. Tools can also enable multimodal interactions - a text-only model can leverage image generation tools like DALL-E, or use OCR and transcription tools to process different input types. Research has shown that tool-augmented models consistently outperform base models, with improvements of over 10% on various benchmarks.
Write actions
Beyond read-only capabilities, tools can perform write actions that modify data sources - like SQL executors updating tables or email APIs sending responses. These write capabilities enable powerful automation workflows, from customer outreach to order processing.
Write actions significantly expand what AI systems can do autonomously, but they also introduce risks. Just as you wouldn’t give unrestricted database access to an intern, careful consideration must be given to what write permissions an AI system receives. Proper security measures and trust validation are crucial when implementing write-enabled tools.
Function calling
Function calling is the mechanism that allows LLMs to use tools. The process typically involves:
- Defining a tool inventory with function names, parameters, and documentation
- Specifying which tools are available for each query
- Controlling tool usage through settings like ‘required’, ‘none’, or ‘auto’
One basic idea here is that LLMs do not run tools, they can only be used to produce intent via prompting, i.e., translating the user’s query into the tool selection and the corresponding arguments. The flow of the function calling is shown as below:
Most LLM model providers support function calling through their APIs, though implementation details vary between providers. And some frameworks like LangChain provide a more structured way to define and use tools. This enables models to effectively act as agents by leveraging external tools. The mechanism under the hood would be the same. The below image shows the function calling mechanism in OpenAI.
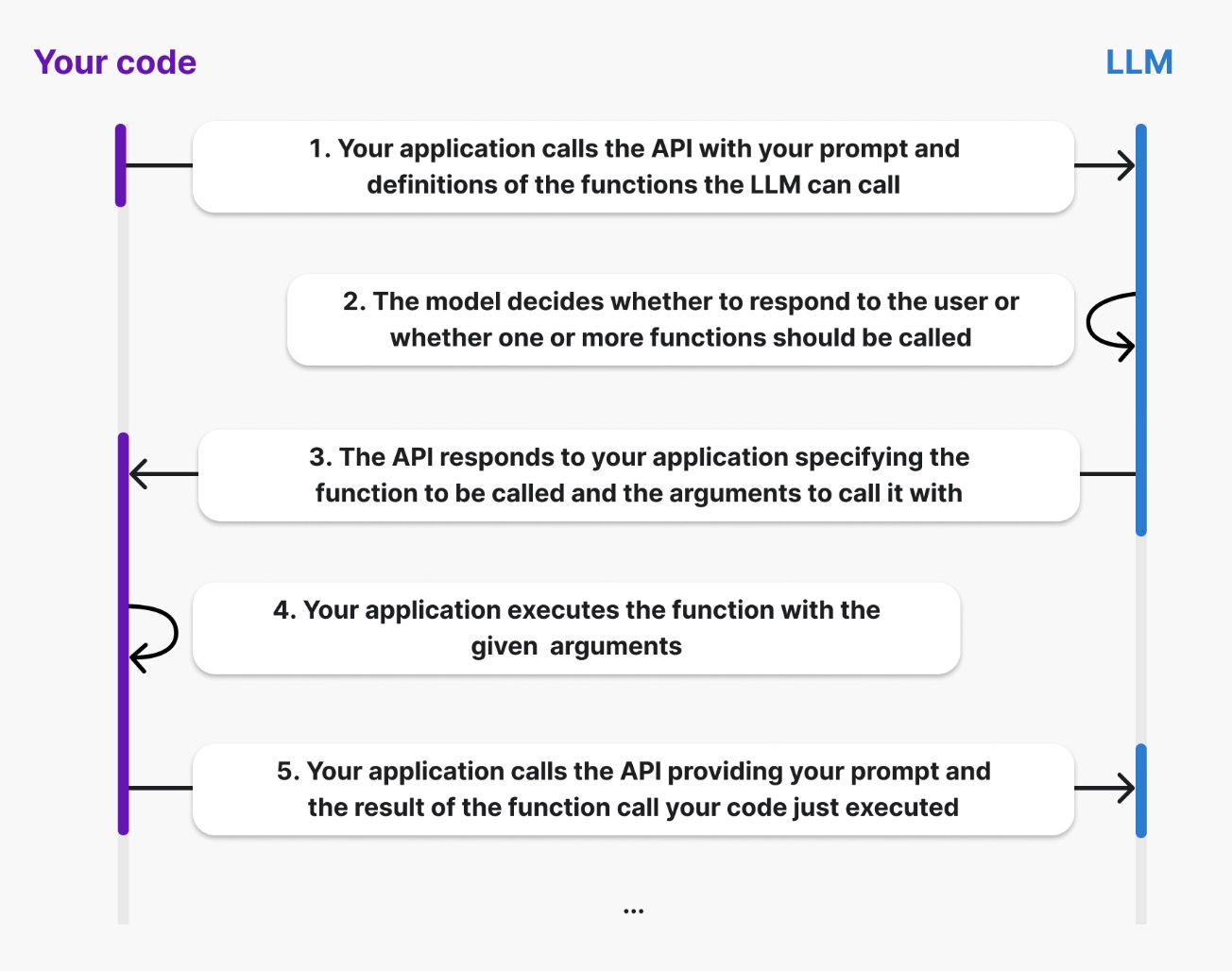
To give more details, let us consider a simple example where we have two tools: kg_to_lbs and cm_to_inches. And the peseudo code for the tools are shown as below:
Tool definition: the logic behind the tools
def kg_to_lbs(kg: float) -> float:
"""Convert kilograms to pounds"""
return kg * 2.20462
def cm_to_inches(cm: float) -> float:
"""Convert centimeters to inches"""
return cm * 0.393701
Tool Decoration: provide the description of the tools so LLM can understand the tools
kg_to_lbs_tool = ToolDecorate(
name="kg_to_lbs",
description="Convert kilograms to pounds",
parameters={properties:
{"kg": {"type": "float",
"description": "The weight in kilograms to convert to pounds"}},
required: ["kg"]},
)
cm_to_inches_tool = ToolDecorate(
name="cm_to_inches",
description="Convert centimeters to inches",
parameters={properties: {"cm": {"type": "float",
"description": "The length in centimeters to convert to inches"}},
required: ["cm"]},
)
Tool calling: the prompt to the LLM
messages = [{"role": "system", "content": [System_Prompt]},
{"role": "user", "content": [User_Prompt]}]
response = model_client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=[kg_to_lbs_tool, cm_to_inches_tool],
tool_choice="auto",
)
Than, given a user query as how many inches is 100 cm, the agent would decide to use the cm_to_inches tool with the parameter value of 100. Than, the response would be expected as below:
response = ModelResponse(
finish_reason='tool_calls',
message=chat.Message(
content=None,
role='assistant',
tool_calls=[
ToolCall(
function=Function(
arguments='{"cm":100}',
name='cm_to_inches'),
type='function')
])
)
At last, the function call would be executed from the parameter as cm_to_inches(100) and the output would be returned to LLM again and than generate responses to the users.
Memory
Memory is another key compoent of the agent. Two types of agentice memory are mainly used which could also be described by the memory patterns present in humans: short-term and long-term memory.
Short-Term Memory (STM)
Short-term memory (STM) is a key component in agent systems that enables temporary storage of information needed for immediate cognitive tasks. In LLMs, STM is implemented through in-context learning within the finite context window of the Transformer architecture. It can be regarded as the working memory of the agent.
STM plays a critical role in agentic applications by providing additional context through the system prompt. For example, in a chat agent, previous interactions are maintained in the prompt to help the system make informed decisions about next actions. The STM can be continuously updated not just with conversation history, but also with information from tool usage, external knowledge queries, and other memory types available to the agent.
Key characteristics of STM include:
- Limited capacity (similar to human STM capacity of ~7 items)
- Temporary storage duration
- Constrained by model context window length
- Critical for maintaining conversation context and task state
Long-term memory
Long-term memory serves as an external vector store that agents can access via fast retrieval when needed. It can be divided into three main types:
Episodic Memory
It stores past interactions and actions performed by the agent. It is similar to RAG but context comes from within the agent system. It is useful when context window is limited or sessions need to be resumed. It enables shared memory across different agent instances. We can think of it as the memory of the agent for their life events.
Semantic Memory
It contains external information available to the agent and includes knowledge about the agent itself. It functions like traditional RAG with external knowledge sources. It is critical for agent’s understanding of its environment and capabilities. It can be regarded as the memory of the agent for their facts or conceptual knowledge.
Procedural Memory
It encompasses system prompts, available tools, and guardrails. The core structure and limitations of the agent is defined here. We can think of it as the memory of the agent for their skills and also it is unconscious memory.
Memory in agents is one of the main components to allow planning that is grounded in the relevant context and there are many aspects to memory that you should take into consideration when building out the agents.
Planning
A complicated task usually involves multiple steps that need to be executed in a specific order. For an agent to successfully complete such tasks, it must first analyze and break down the overall goal into smaller subtasks. The agent then needs to determine the dependencies between these subtasks and create a structured plan that outlines the sequence of actions required. It is called planning.
To solve complex tasks, the agent usually goes through the following proccess:
- Plan Generation
- Break down task into manageable steps
- Create sequence of actions
- Plan Validation (Self-reflection)
- Review and evaluate the plan
- Generate new plan if needed
- No execution here
- Execution
- Carry out planned actions
- Call required functions
- Powered by the function calling mechanism
- Outcome Review (Self-reflection)
- Evaluate results
- Fix errors if needed
- Create new plan if goal not met
The agent could automate the above steps from plan generation, plan validation, and execution. But in reality, humans can be involved at any stage to intervene the process and reduce the potential risks.
Let us check the above components one by one.
Plan Generation
It can be understood as the task decomposition. The agent would break down the task into smaller sub-tasks and multiple steps. The most simple way to do this is using prompt engineering to guide the agent.
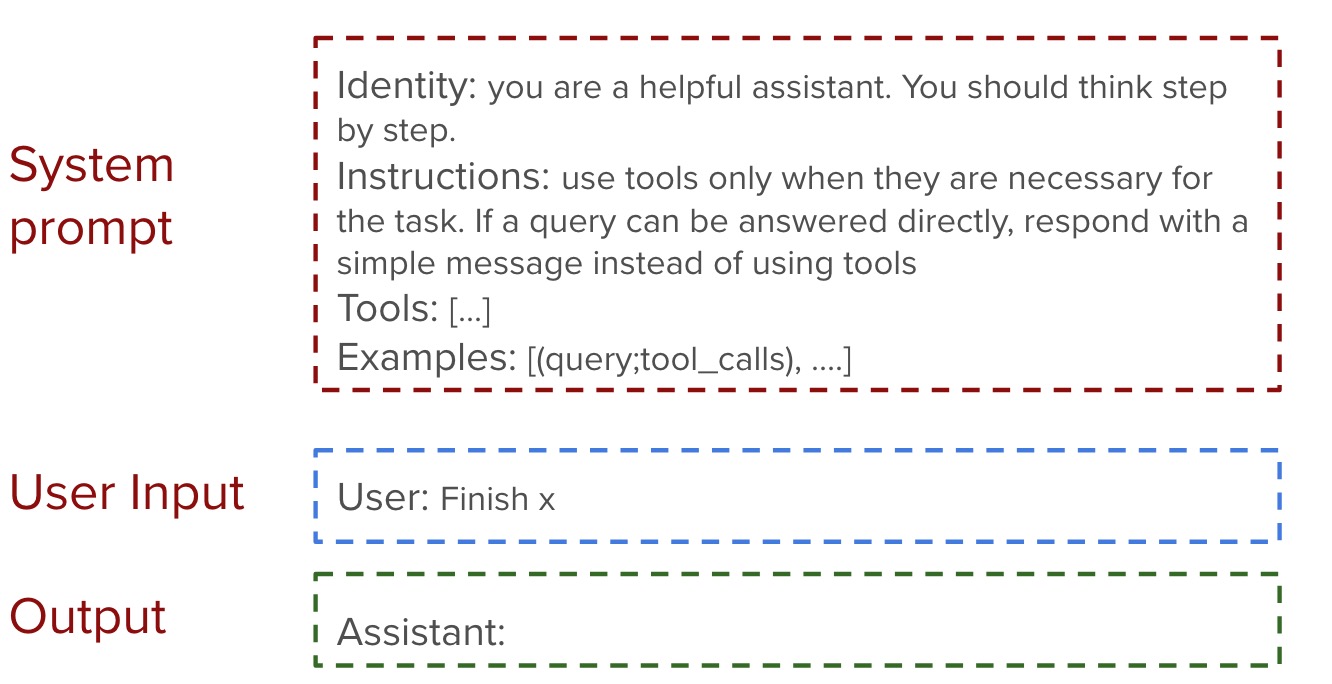
In the above example, we give the agent the access to external tools and we guide the agent to think step by step. It is called Chain of thought which force the model to decompose the task into smaller and simpler steps.
According to huyenchip’s blog post, AI models can hallucinate action sequences and parameters, potentially causing invalid function calls, but general model improvement techniques can enhance planning capabilities. The tips for making an agent better at planning are shown as below:
- Write a better system prompt with more examples.
- Give better descriptions of the tools and their parameters so that the model understands them better.
- Rewrite the functions themselves to make them simpler, such as refactoring a complex function into two simpler functions.
- Use a stronger model. In general, stronger models are better at planning.
- Finetune a model for plan generation.
In practice, planning generation could be completed in two ways which will bring us workflows and agents. This categorization is from the recent blog post by Anthropic.
Workflow
Systems where LLMs and tools are orchestrated through predefined code paths. Five major patterns are reviewed and visualized as below:
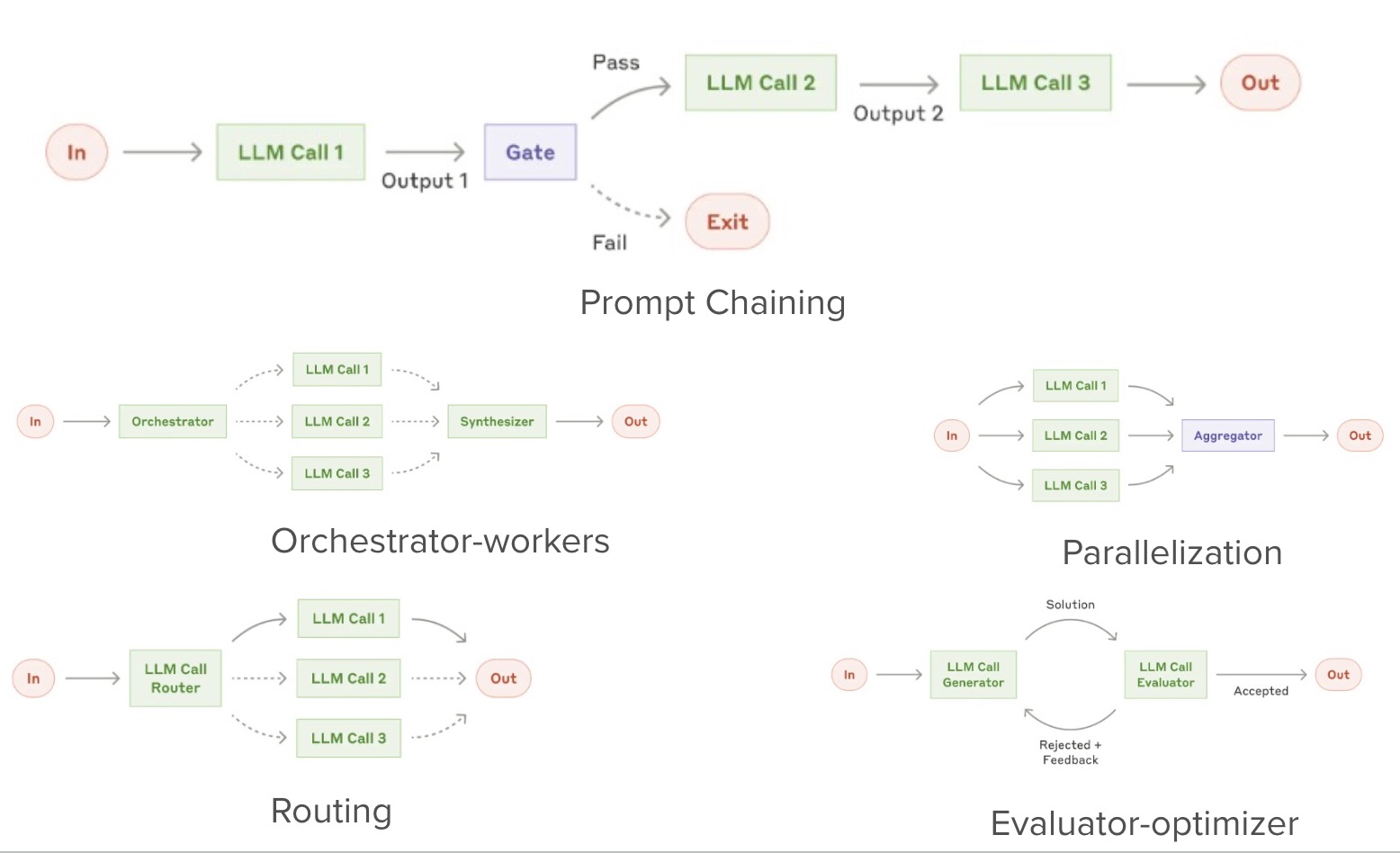
The details could be found in that blog. But each pattern would have its own suitability for different scenarios. Overall, the workflow is able to bring predictability and control to the system. It is very useful to solve those well-defined tasks.
Agent
Here, the narrow definition of Agents is the systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
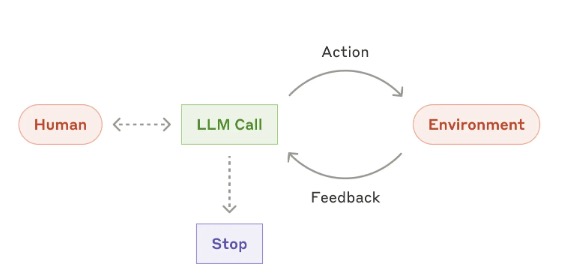
Agents are AI systems that use LLMs to handle tasks autonomously. They take user input, make plans, and execute actions while collecting feedback. Though advanced, they are essentially LLMs using tools in a loop, requiring well-designed tools to work effectively. And the another capability of the agent is the self-reflection, which also decide the design patterns behind various kinds of agents.
Self Reflection
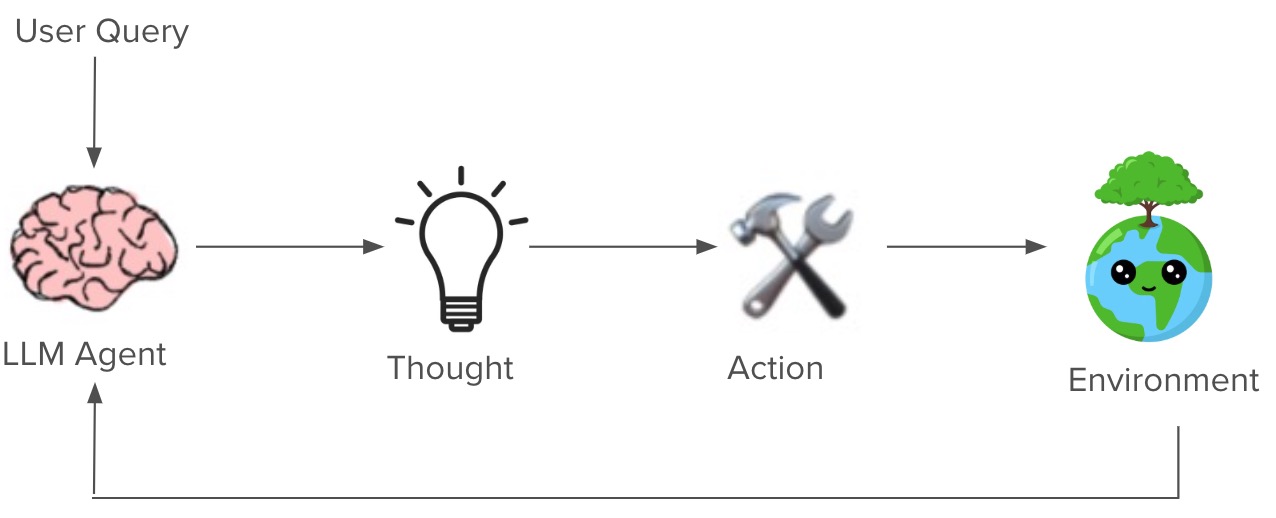
Self-reflection enables autonomous agents to continuously improve by analyzing their past decisions and learning from mistakes. As we can see, it can enable the agent to correct is planning and execution. This capability is essential for real-world applications where perfect execution on the first try is rare. There are many designing patterns for self-reflection, i.e., when and where to use reflection. In the following, we will briefly introduce two of them: ReACT and Plan-and-Execute.
ReAct framework (Yao et al. 2023) combines reasoning and acting capabilities within Large Language Models (LLMs). ReAct expands the traditional action space to include both:
- Task-specific discrete actions (e.g., API calls, database queries)
- Natural language reasoning traces
The flow is shown as below:
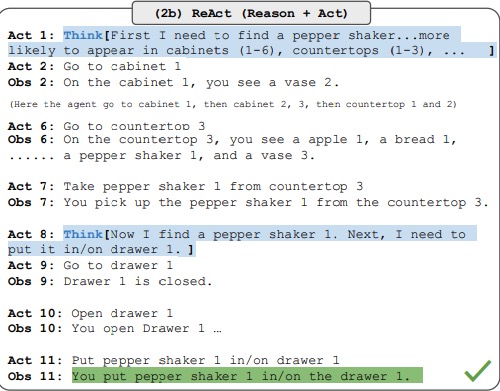
The agent is typically prompted, using examples, to generate outputs in the following format:
Thought 1: ...
Action 1: ...
Observation 1: ...
... (Repeated many times until the task is completed)
As you can see from the original paper, the ReACT framework is able to improve the agent’s performance significantly.

The ReACT takes advantage of Chain-of-thought prompting to make a single action choice per step. While this can be effect for simple tasks, it has a couple main downsides:
- It requires an LLM call for each tool invocation.
- The LLM only plans for 1 sub-problem at a time. This may lead to sub-optimal trajectories, since it isn’t forced to “reason” about the whole task.
One way to overcome these two shortcomings is through an explicit planning step. One of those approaches is called Plan-And-Execute.
Plan-And-Execute operates in three key stages:
- Planning: An LLM creates a detailed step-by-step plan upfront, i.e., a task list
- Execution: Specialized executors carry out each planned step using appropriate tools
- Evaluation & Replanning: The agent assesses results and replans if needed
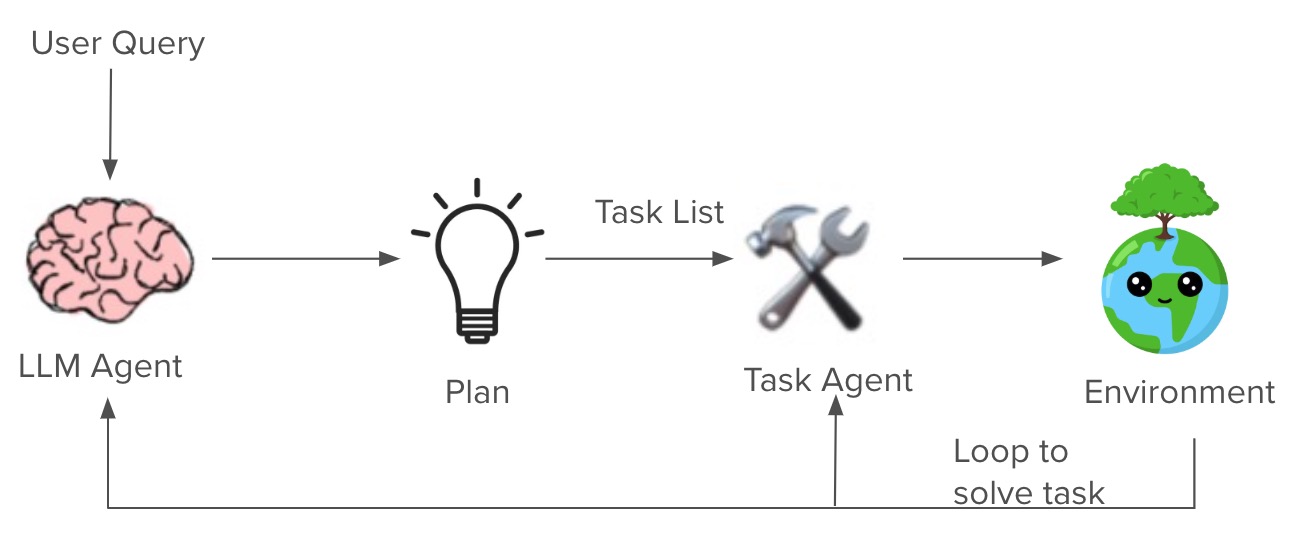
For example, if asked to “Research and summarize recent AI breakthroughs”:
Plan generated:
- Search for AI papers from last 6 months
- Filter for high-impact discoveries
- Create summary of key findings
- Format into readable report
The executor would then methodically work through each step, using tools like research databases, text analysis, and document formatting.
Once execution is completed, the agent is called again with a re-planning prompt, letting it decide whether to finish with a response or whether to generate a follow-up plan (if the first plan didn’t have the desired effect).
The key advantage is efficiency - by planning upfront, the agent minimizes redundant LLM calls while maintaining the flexibility to adapt when needed through replanning.
So far, we’ve assumed that the agent automates all three stages: generating plans, validating plans, and executing plans. In reality, humans can be involved at any stage to aid with the process and mitigate risks. For example, humans can help to provide plans, check plans, and execute plan steps. And also for some key and high risk operations, humans can help to approve the operations and also complete the operations.
In the blog shared by Anthropic, they shared the core principles of building effective agents as below:
- Maintain simplicity in your agent’s design.
- Prioritize transparency by explicitly showing the agent’s planning steps.
- Carefully craft your agent-computer interface (ACI) through thorough tool documentation and testing.
And also, they highlighted the importance of the simplicity in the agent’s design. It is the same as all of the previous ML systems. Always, start with the simple prompts, optimize them with comprehensive evaulation, and add multi-step agentic systems. The increased complexity should be added step by step. And what is important is that there should be a measure to validate the agent’s performance over the added complexity.
Final Thoughts
Now, let us recall the AI levels defined by OpenAI. Agents can take actions and complete tasks. With agents, the way that humans work could be redefined. Humans would only need to set targets, provide resources, and review the results, while AI would do the rest. Sounds familiar, right? Everyone would become an engineering manager and agents would be your SDEs.
Take Cursor as an example - it’s one of the most popular agentic AI products today. Like many agentic AI tools, it provides an amazing initial experience that feels magical. However, with extended use, limitations become apparent as it can get stuck in loops or fail to make progress. Despite these current limitations, I believe tools like Cursor offer an exciting glimpse into the future. The key is learning to effectively leverage LLMs as assistants rather than fully autonomous agents. The most promising path forward likely involves AI agents working collaboratively with humans in the loop - combining the strengths of both. I’m excited to see how this human-AI partnership evolves.

References
- Askell, A., Bai, Y., Chen, A., Chan, D., DasSarma, N., Drain, D., ... & Kaplan, J. (2024). Building Effective Agents Through Human Feedback and AI Training. Anthropic Research . [link]
- Lilian Weng (2023). Agentic AI. Lilian Weng's Blog . [link]
- Huyen Chip (2025). Agents. Huyen Chip's Blog . [link]
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 . [link]
- Langchain (2024). Planning Agents. Langchain Blog . [link]