
Server LLM with Ollama
If we want to run LLM on a local setup or in Docker quickly and you are concerned about the data privacy issuees, Ollama is here for us which is super easy to use. Here, we will explore how to use Ollama to run LLM locally.
What is Ollama?
Ollama is an open-source framework that allows users to run, develop and deploy large language models (LLMs) locally. It offers an accessible way to harness LLM capabilities on personal hardware while maintaining control over data and infrastructure. Key features includes:
- Supports multiple LLM models like Llama 2, Mistral, Gemma, CodeLLama, and Falcon
- Provides user-friendly command-line interface
- Compatible with macOS, Linux and Windows
- Can be deployed using Docker containers and Kubernetes
- Enables local model training and inference without paid API costs
- Simple installation and model management through basic commands
The git project and offical website are available for more information.
You have multiple options to install Ollama such as download it from the offical website or run in a Docker container.
Ollama Setup
Start the Ollama server
ollama serve
This will start the Ollama server and you will see the following output:

Than, the following commands can be used to use Ollama on the command line:
ollama pull— This command is used to pull a model from the Ollama model hub.ollama rm— This command is used to remove the already downloaded model from the local computer.ollama cp— This command is used to make a copy of the model.ollama list— This command is used to see the list of downloaded models.ollama run— This command is used to run a model, If the model is not already downloaded, it will pull the model and serve it.
To interact with the model, you can use the ollama run command. For example, to run the llama3.2 model, you can use the following command:
ollama run llama3.2:1b
This will start the model and you can interact with it.
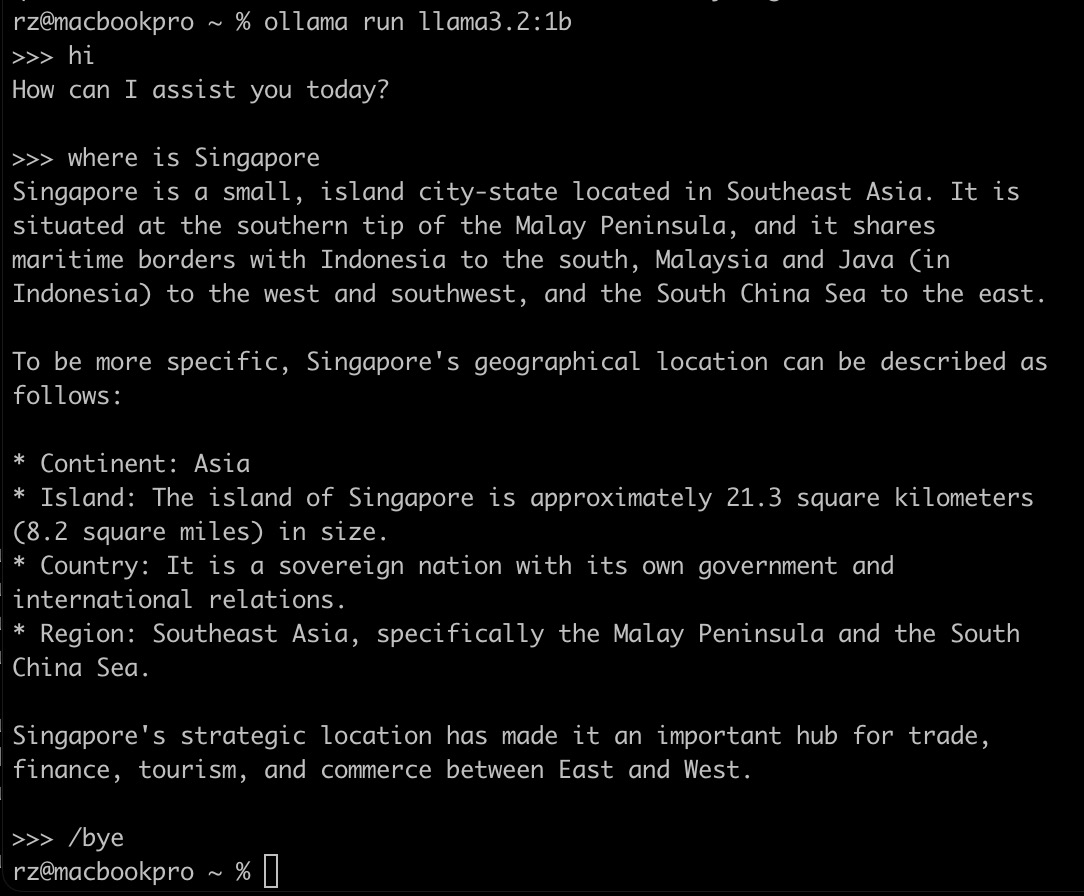
Or you can call the API endpoint to interact with the model.

You can see the output below. you will find the response as JSON, and we should be able to extract the response from the “response” key.
{"model":"llama3.2:1b","created_at":"2024-10-29T13:03:13.29189Z","response":"Singapore is an island city-state located at the southern tip of the Malay Peninsula in Southeast Asia. It is situated approximately 1,480 kilometers (914 miles) southeast of mainland Malaysia and is part of the region known as the Strait of Malacca.\n\nTo be more specific, Singapore is bordered by:\n\n* Indonesia to the south\n* Malaysia to the north and east\n\nIt is a small island with a total area of about 720 square kilometers (278 square miles), making it one of the smallest countries in the world. Despite its tiny size, Singapore is a major economic and financial hub, known for its high standard of living, strong economy, and multicultural society.","done":true,"done_reason":"stop","context":[128006,9125,128007,271,38766,1303,33025,2696,25,6790,220,2366,18,271,128009,128006,882,128007,271,9241,374,21181,30,128009,128006,78191,128007,271,92928,374,459,13218,3363,21395,7559,520,279,18561,11813,315,279,80240,50714,304,36664,13936,13,1102,374,31183,13489,220,16,11,11738,41668,320,24579,8931,8,42552,315,51115,28796,323,374,961,315,279,5654,3967,439,279,83163,315,8560,582,936,382,1271,387,810,3230,11,21181,374,77317,555,1473,9,24922,311,279,10007,198,9,28796,311,279,10411,323,11226,271,2181,374,264,2678,13218,449,264,2860,3158,315,922,220,13104,9518,41668,320,16949,9518,8931,705,3339,433,832,315,279,25655,5961,304,279,1917,13,18185,1202,13987,1404,11,21181,374,264,3682,7100,323,6020,19240,11,3967,369,1202,1579,5410,315,5496,11,3831,8752,11,323,75416,8396,13],"total_duration":1537113916,"load_duration":19802541,"prompt_eval_count":29,"prompt_eval_duration":96000000,"eval_count":136,"eval_duration":1420000000}%
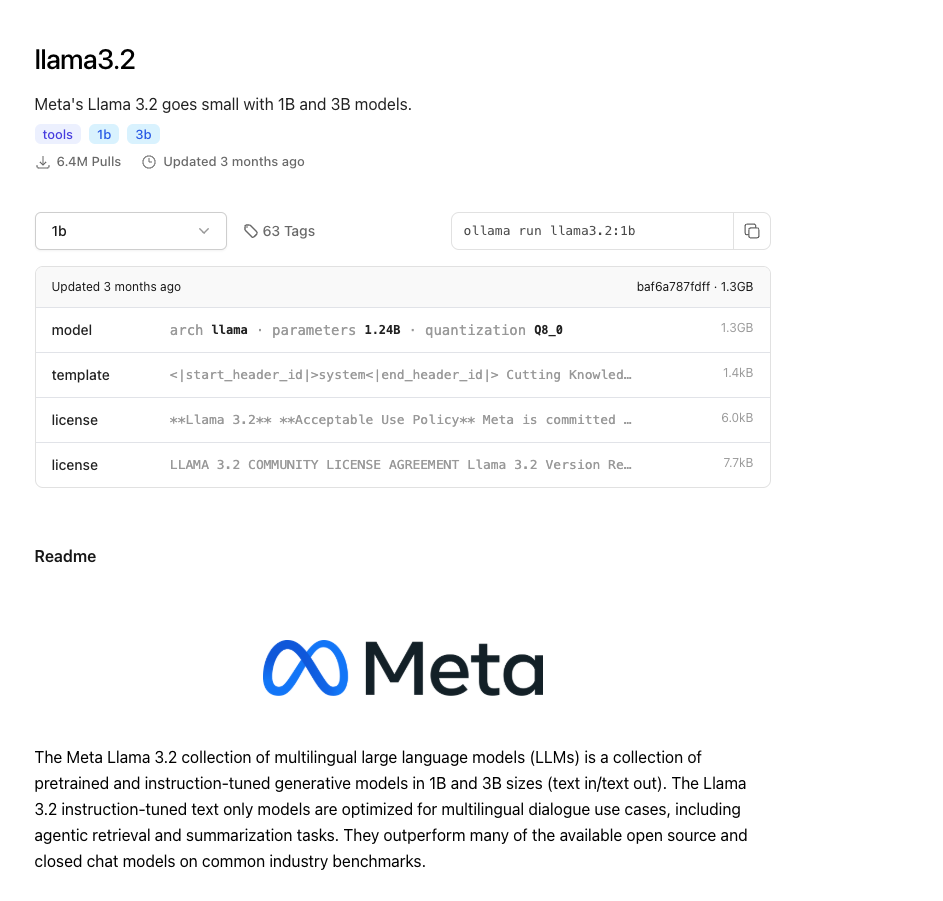
Another good thing about Ollama is that you can use the details of the model easily from their webiste. For example, all info from llama3.2 could be found here. The info is pretty clear and easy to be understood.
Custom LLM with a prompt
In Ollama, there is a file called model file which is the blueprint to create and share models. To view the model file, you can use the following command:
ollama show --modelfile llama3.2:1b
As shown below, the model file’s format is fixed as:
# comment
INSTRUCTION arguments
And all of entries are as:
| Instruction | Description |
|---|---|
| FROM (required) | Defines the base model to use. |
| PARAMETER | Sets the parameters for how Ollama will run the model. |
| TEMPLATE | The full prompt template to be sent to the model. |
| SYSTEM | Specifies the system message that will be set in the template. |
| ADAPTER | Defines the (Q)LoRA adapters to apply to the model. |
| LICENSE | Specifies the legal license. |
| MESSAGE | Specify message history. |
Than, we can create a Modelfile. For example,
FROM qwen2.5:3b
SYSTEM """
You are my personal assistant and will always reply in Chinese
"""
Than, you can create and run the model with the following command:
ollama create pabot -f ./Modelfile
ollama run pabot
And you will see the following output:

The more details about the model file, you can refer to this link.
Ollama WebUI
Open WebUI is an extensible, self-hosted UI that runs entirely inside of Docker. It can be used either with Ollama or other OpenAI compatible LLMs, like LiteLLM or my own OpenAI API for Cloudflare Workers.
Assuming you already have Docker and Ollama running on your computer, installation is super simple.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
The simply go to http://localhost:3000, make an account, and start chatting away!
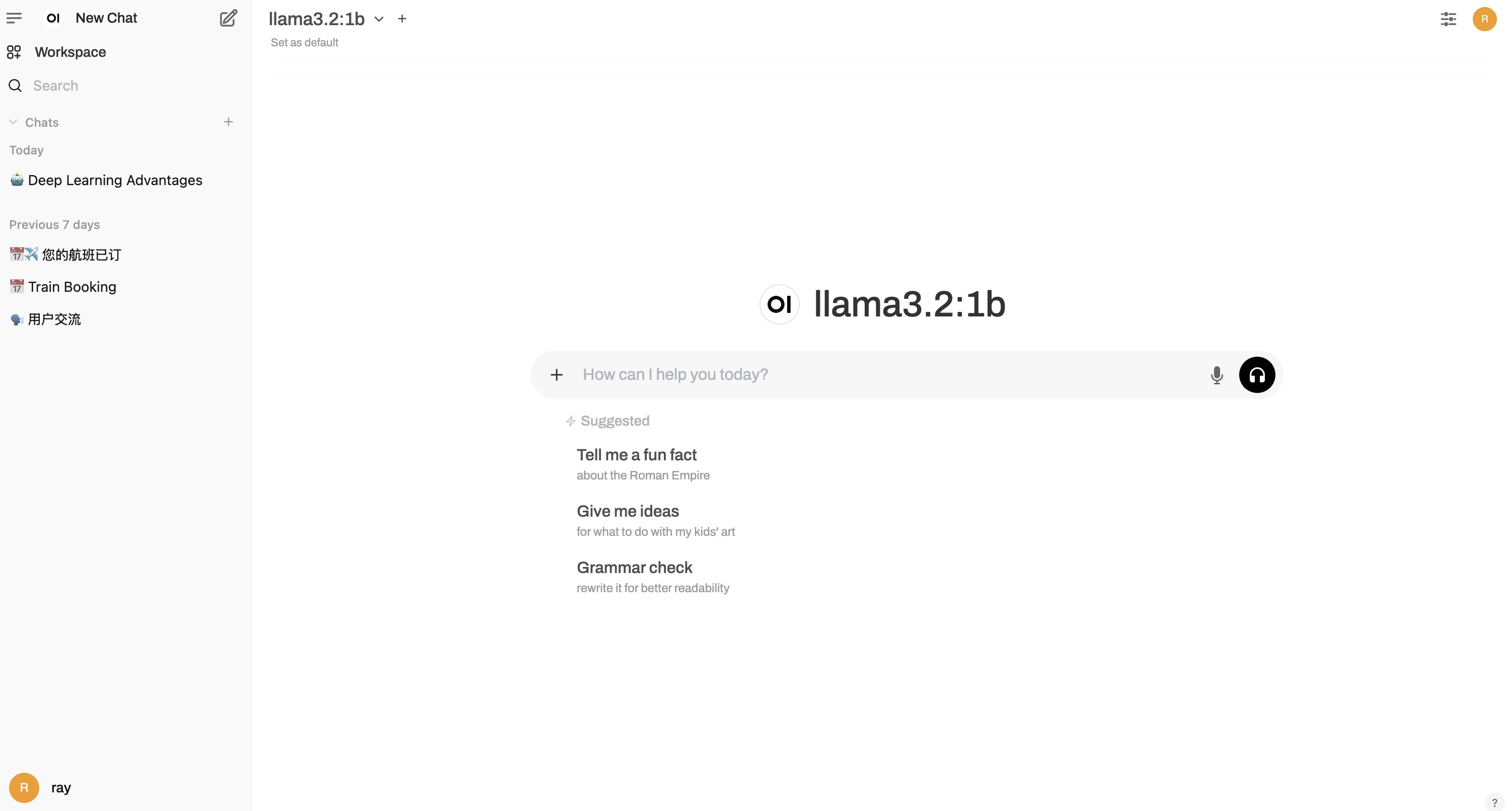
Than, it is very easy to use the Ollama WebUI to chat with the model. It is very similar to the ChatGPT WebUI with lots of powerful features. You can swith to all Ollama models that you have installed. And you can also set all of parameters related to the model from the UI such as temperature, top_p, top_k, etc.
Others
Ollama can be used not only for chat and text generation, but also can be combined with code generation models and IDE plugins to create powerful code completion assistants. For example, using the DeepSeek Coder 6.7B model and VS Code plugin Continue, you can achieve efficient and convenient code completion functionality. More details could be found here.
And Ollama also supports running models with Docker. This is very useful to build microservices with LLM using Ollama. And also to scale the system, we can easily deploy our applications in the docker ecosystem, such as OpenShift, Kubernetes, and others.
Ollama also can be used as a drop in replacement with the OpenAI libraries. The sample code from their documentation is as follows:
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
# required but ignored
api_key='ollama',
)
chat_completion = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': 'Say this is a test',
}
],
model='llama3.2',
)
And it also supports the multi-mode models. For example, Large Language-and-Vision Assistant (LLaVA) model is supported by Ollama here.
Basically, Ollama helps us to run large language models, locally in very easy and simple steps. Hope this article give you a basic sense about Ollama and how to use it.