
Parameter Efficient Fine Tuning: LoRA and QLoRA
Parameter Efficient Fine-Tuning (PEFT) is a technique designed to fine-tune models while minimizing the need for extensive resources and cost. PEFT is a great choice when dealing with domain-specific tasks for fine-tuning. In this article, we will review two most widely used and effective approaches: Low-Rank Adaptation (LoRA) & Quantized Low-Rank Adaptation (QLoRA).
LoRA
Low-rank adaptation provides a way to fine-tune the model with a small number of parameters. It is a technique that adds trainable low-rank matrices to the original model to adapt it to the target task. The idea is to add trainable parameters to the original model to adapt it to the target task.
LoRA works by adding a trainable adapter layer to all of weight matrices. The key idea is to keep the original pre-trained model weights frozen while introducing a small number of trainable parameters through low-rank decomposition. This approach significantly reduces the memory and computational requirements during fine-tuning.
The main components of LoRA are:
-
Frozen Pre-trained Weights: The original model weights (W) remain unchanged during training, preserving the knowledge learned during pre-training.
- Low-rank Adapter: Two matrices WA and WB are introduced with dimensions d×r and r×d respectively, where:
- d is the original weight dimension
- r is the chosen rank dimension (r « d)
- The smaller r value reduces training time and memory requirements but may impact performance
- Larger r values increase training costs but allow for better task adaptation
- Training Process:
- The output is computed by combining the frozen weights and low-rank adapter paths
- During training, only WA and WB are updated through backpropagation
- The loss function guides the optimization of these adapter weights
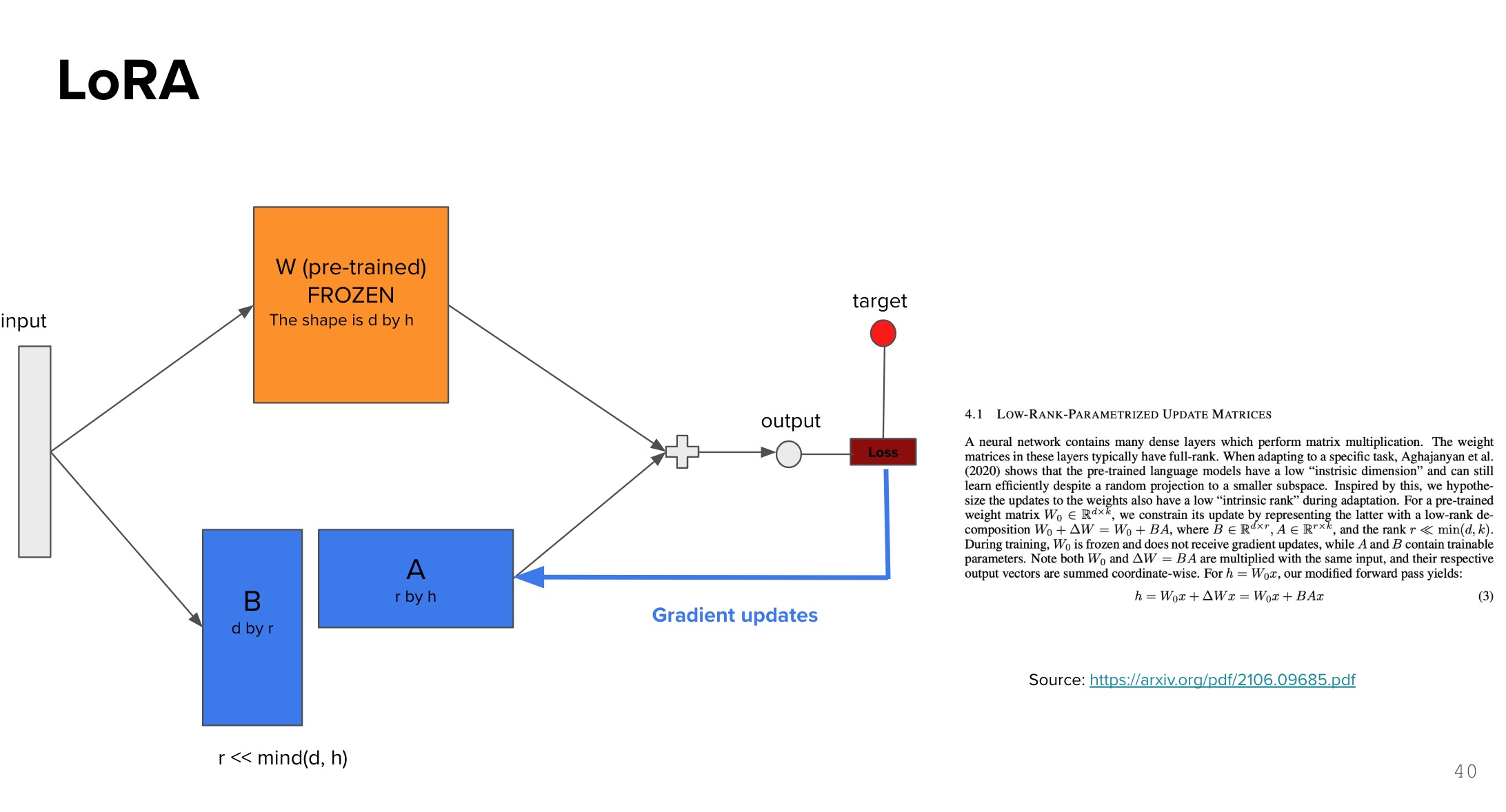 LoRA architecture showing frozen pre-trained weights and trainable low-rank adapters
LoRA architecture showing frozen pre-trained weights and trainable low-rank adapters
The rank dimension r is a critical hyperparameter that controls the trade-off between efficiency and model capacity. A smaller r leads to faster training and lower memory usage but may not be able to capture the fine-tuning task, while a larger r enables better task performance at the cost of increased resources with more chances of overfitting. And I do not have a good intuition on how to choose the right r. As all of hyperparameters, it would be explored for each model and each dataset.
Another trick is to which layers to apply LoRA. For the normal transformer model, LoRA can be applied to the query, key and value matrics, also the projection and MLP layers.
One more thing is that during forward pass, the LoRA weights are added to the pretrained weights with a scaling factor. This is to ensure that the LoRA weights do not dominate the original weights during training. The scaling factor is defined as alpha / r where alpha is a constant value that is defined by the user and r is the rank dimension. The alpha value is usually set to 2 times of the rank dimension as a common rule of thumb.
QLoRA
QLoRA is a quantization-aware LoRA. It is a technique that quantizes the weights of the model to reduce the memory usage and computational requirements during fine-tuning. The idea is to quantize the pretrained weights to 4-bit precision and uses paged optimizers to handle memory spikes during backpropagation. The memory usage could be reduced further compared to LoRA. But the training runtime would be slower due to the additional quantization and dequantization operations of the pretrained model weights in QLoRA.
There is a table showing the tuning recommendation for LoRA and QLoRA from the Blog Cloud 2024.
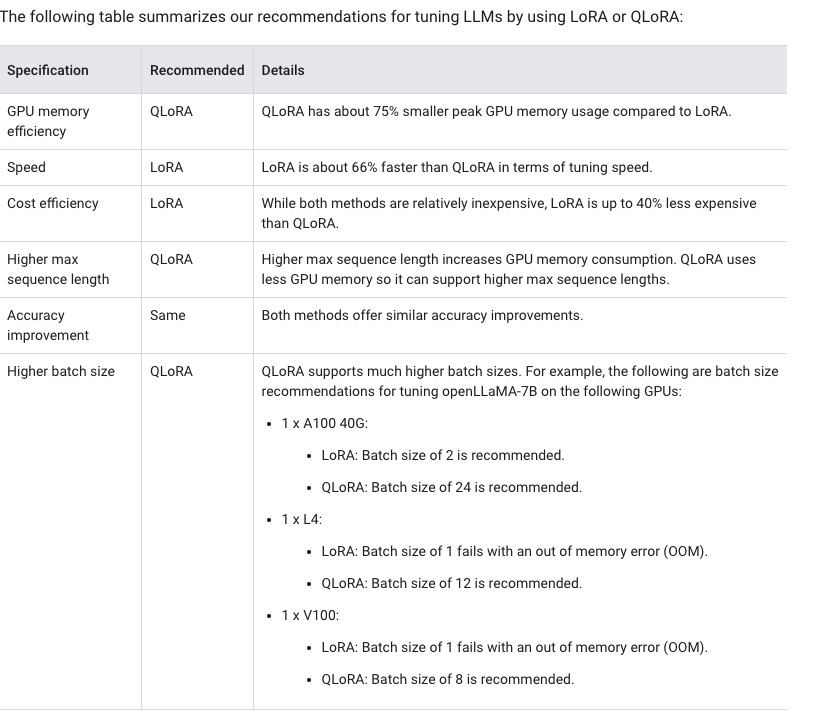 LoRA vs QLoRA
LoRA vs QLoRA
References
- NVIDIA Developer Blog (2023). Mastering LLM Techniques: A Comprehensive Guide to Inference Optimization. NVIDIA Developer Blog . [link]
- Escobar, Manuel (2023). Memory Requirements for LLM Training and Inference. Medium . [link]
- Hugging Face (2024). Model Memory Anatomy. Hugging Face Documentation . [link]
- Google Cloud (2024). LoRA and QLoRA. Vertex AI Generative AI . [link]